.png)
NAS 新技能:Kreuzberg 全格式提取文字
本文最后更新于 2026-03-05,文章内容可能已经过时。
家里 NAS 除了存文件,还能跑服务。今天说的这个叫 Kreuzberg,一个开源的文档内容提取工具,丢给它一个文件,它把里面的文字还给你。
支持的格式挺全:PDF、Word、Excel、PowerPoint(新旧格式都行)、图片 OCR、HTML、邮件、压缩包。部署在 NAS 上之后,局域网里任何设备都能调用它。对家庭用户来说,扫描件转文字、整理 PDF 资料、给本地 AI 工具喂文档,都能用上。官方有现成的 Docker 镜像,同时支持 x86 和 ARM64,飞牛 fnOS 直接可以用,不需要自己编译。
先建好目录
打开 fnOS 文件管理器,进「我的文件」,在 Docker 文件夹下新建 kreuzberg,里面再建两个子文件夹:
/vol1/1000/Docker/kreuzberg/
├── cache/ ← 模型缓存,首次运行会自动下载
└── config/ ← 配置文件,可选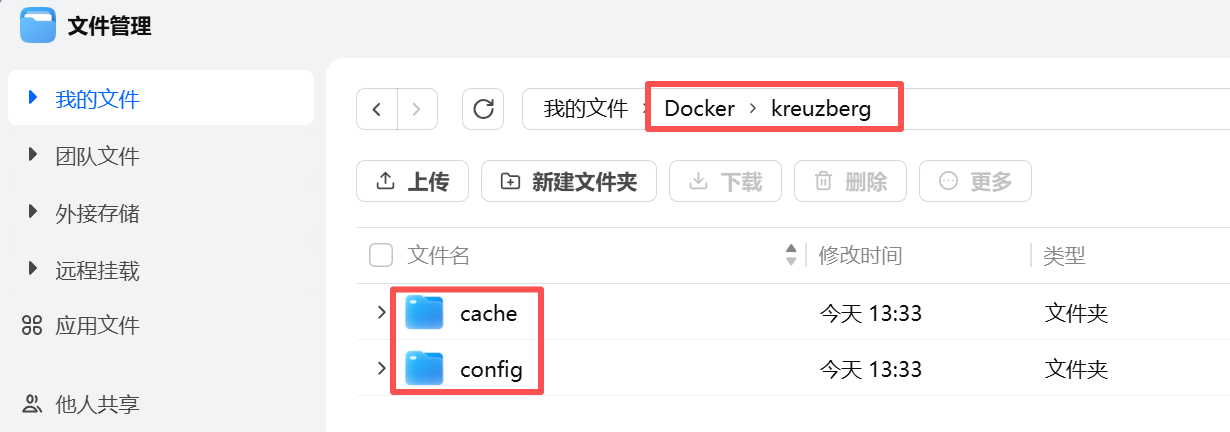
创建 Docker 项目
打开 fnOS 桌面的 Docker 应用,点左侧「Compose」,点「新增项目」。
创建项目页面,按需填写:
项目名称:
kreuzberg路径:
/vol1/1000/Docker/kreuzberg
然后把下面的 compose 内容粘贴进编辑框,粘贴完,勾选「创建项目后立即启动」,点「创建」。
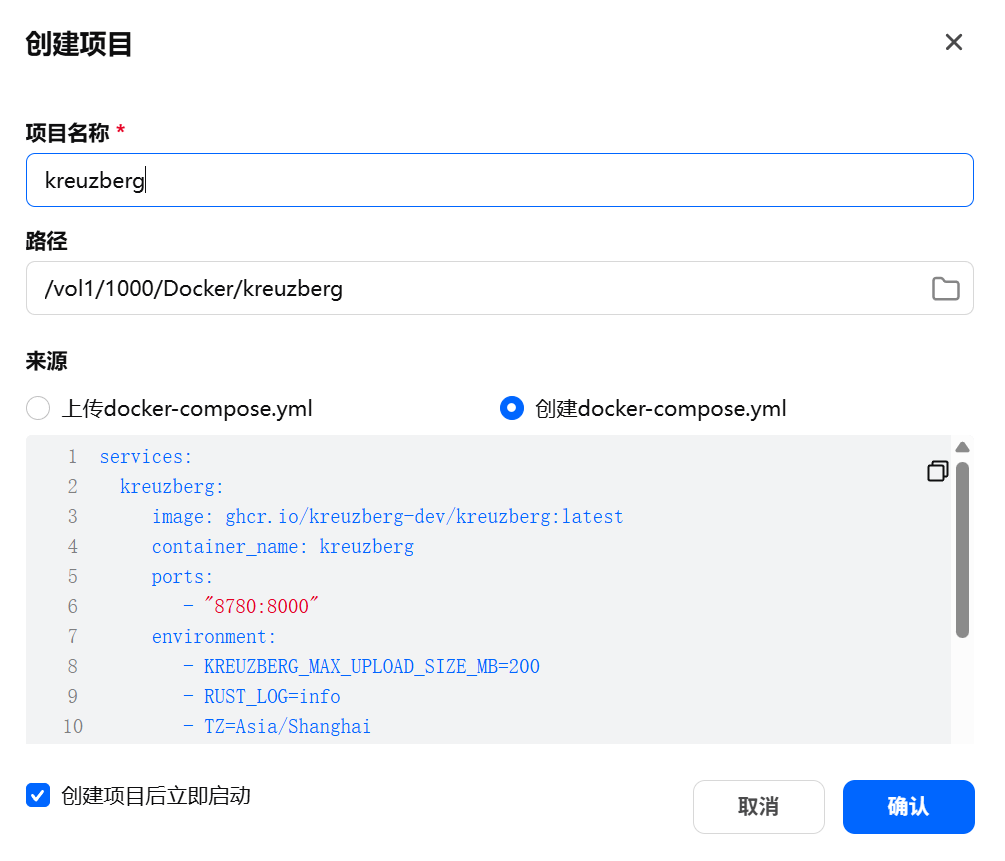
docker-compose.yml
普通家用选这个,镜像约 1~1.3GB,OCR 和常见格式都支持:
services:
kreuzberg:
image: ghcr.io/kreuzberg-dev/kreuzberg:latest
container_name: kreuzberg
ports:
- "8780:8000"
environment:
- KREUZBERG_MAX_UPLOAD_SIZE_MB=200
- RUST_LOG=info
- TZ=Asia/Shanghai
volumes:
- /vol1/1000/Docker/kreuzberg/cache:/app/.kreuzberg
restart: unless-stopped
healthcheck:
test: ["CMD", "kreuzberg", "--version"]
interval: 30s
timeout: 10s
retries: 3
start_period: 10sNAS 内存比较小(4GB 以下)的话,加上资源限制:
deploy:
resources:
limits:
memory: 1G
cpus: "1"
reservations:
memory: 512M
cpus: "0.5"等镜像拉取完
第一次启动会从 ghcr.io 拉取镜像,大小 1~1.3GB,5~20 分钟不等,取决于网速。在 Docker 应用「容器」标签里能看到进度。变成绿色「运行中」就好了。
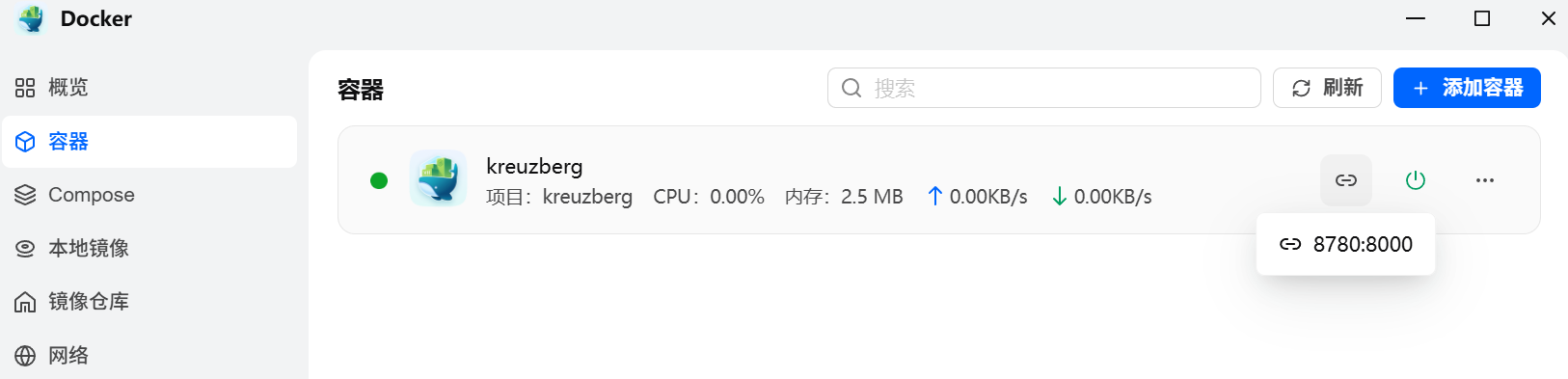
验证一下
在局域网里任意设备的浏览器输入:
http://你的NAS的IP:8780/health
返回内容就说明跑起来了。
用法
API 接口
提取单个文件:
curl -F "files=@/path/to/document.pdf" http://NAS的IP:8780/extract同时提取多个文件:
curl -F "files=@report.pdf" \
-F "files=@contract.docx" \
http://NAS的IP:8780/extract扫描件(拍照的合同、图片格式的文件)直接发过去,Kreuzberg 会自动调用 OCR:
curl -F "files=@scanned.jpg" http://NAS的IP:8780/extract只想要纯文字,加 format 参数:
curl -F "files=@document.pdf" \
-F "format=text" \
http://NAS的IP:8780/extract配合本地 AI 工具
如果 NAS 上跑了 Ollama 或 Open WebUI,可以先用 Kreuzberg 把 PDF 里的文字提取出来,再把文字发给模型。很多模型处理纯文字比处理 PDF 格式稳定得多。
把提取结果存成 txt 文件的脚本:
#!/bin/bash
# 用法:bash extract.sh 合同.pdf
curl -s -F "files=@$1" \
http://NAS的IP:8780/extract \
| python3 -c "import sys,json; print(json.load(sys.stdin)[0]['content'])" \
> ".txt"批量处理
把一个目录下的 PDF 全部提取一遍,结果追加到同一个 JSON 文件里:
for f in /vol1/1000/documents/*.pdf; do
echo "处理:$f"
curl -s -F "files=@$f" http://localhost:8780/extract \
>> /vol1/1000/documents/extracted_all.json
echo "" >> /vol1/1000/documents/extracted_all.json
doneMCP 服务器模式
支持 MCP 协议的 AI 工具(比如 Claude Desktop)可以直接把 Kreuzberg 挂成文档读取工具。在 compose 里加一行 command:
services:
kreuzberg:
image: ghcr.io/kreuzberg-dev/kreuzberg:latest
command: mcp
ports:
- "8780:8000"
volumes:
- /vol1/1000/docker/kreuzberg/cache:/app/.kreuzberg
restart: unless-stopped然后在 AI 工具的 MCP 配置里填 http://NAS的IP:8780。
常用环境变量
从局域网其他设备的网页里调用 API,需要设置 CORS。允许所有来源:
- KREUZBERG_CORS_ORIGINS=*遇到问题
容器起不来,在 Docker 应用里点容器名,看「日志」标签。端口 8780 被占用是最常见的原因,把 compose 里 8780:8000 改成 8787:8000 再试。
上传文件报错,检查文件大小有没有超过 KREUZBERG_MAX_UPLOAD_SIZE_MB 的设置。
挂载目录权限报错,在 fnOS 终端执行:
chown -R 1000:1000 /vol1/1000/docker/kreuzberg/cache容器内用的是非 root 用户(UID 1000),目录权限对不上就会报错。
第一次调用 OCR 功能时,Kreuzberg 会自动下载模型文件,90MB~1.2GB 不等,只发生一次,下载完缓存在 cache 目录里。第一次提交文件等几分钟是正常的。
项目地址:github.com/kreuzberg-dev/kreuzberg
官方文档:docs.kreuzberg.dev