Codex 接入本地大模型:一次跑通的环境配置记录
本文最后更新于 2026-05-18,文章内容可能已经过时。
最近不少同行在问,Codex Desktop App 能不能不连云端、直接挂本地模型跑。答案是可以,配合 Ollama 即可实现。本文记录一套笔者已实测跑通的环境配置,步骤本身并不复杂,但其中几个细节容易踩坑,整理出来供各位参考。
环境清单
客户端:Codex Desktop App
后端驱动:Ollama v0.24
本地模型:Gemma 4(机器配置充裕时可换 Qwen 3.6)
国内网络环境下,Ollama 官网与 GitHub Release 的连通性并不稳定,建议提前准备镜像源或代理。模型文件本身体积可观,Gemma 4 单文件数 GB 起步,Qwen 3.6 更大,下载前请预留充足磁盘空间。
一、安装或升级 Ollama
Ollama 版本不能低于 v0.24。可前往官网下载安装包,也可直接在终端执行下面这条命令完成安装或更新:
curl -fsSL https://ollama.com/install.sh | sh如果官网脚本拉取失败,可改用国内镜像或挂代理执行。macOS 用户也可以直接通过 Homebrew 安装,省去手动处理脚本的环节。
二、启动 Codex 专用通道
在终端执行:
ollama launch codex-app这条命令会让 Ollama 接管 Codex 的后端连接。
三、选择运行模式与模型
启动后会提示选择运行模式:
Cloud 版:需要注册并购买 Ollama 的云服务。
本地版(推荐):模型文件下载至本机直接运行,数据不出本地,隐私和合规层面都更可控。
模型选择上:
Gemma 4:本次配置选用的就是它,速度可以接受,回答质量足以应对日常代码补全。
Qwen 3.6:中文场景下表现更稳,参数量更大,对显存的要求也更高,建议机器配置充裕时再考虑。
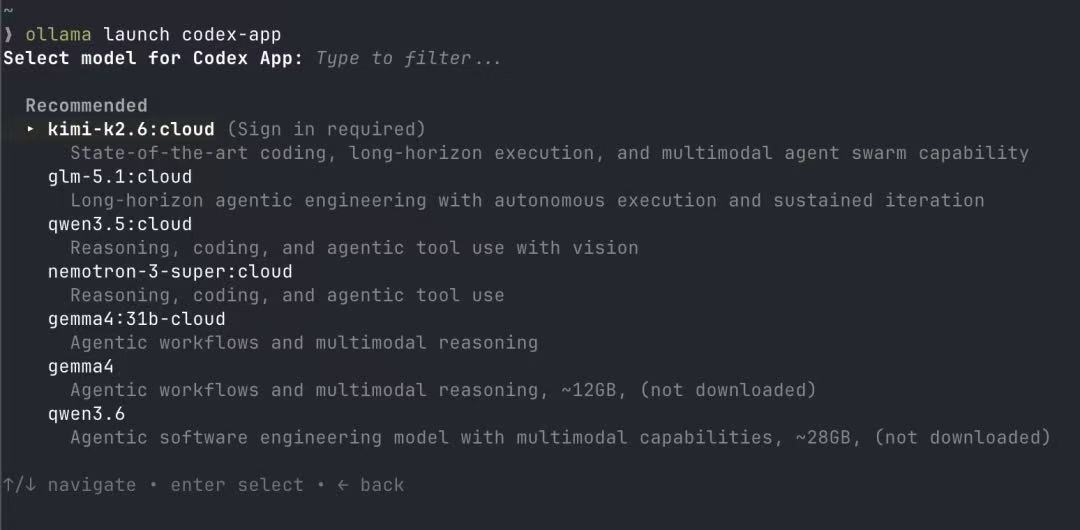
如果是 16G 内存的轻薄本,建议直接选 Gemma 4;32G 起步的工作站,或带独显的 Mac,可以尝试 Qwen 3.6。
四、自动下载模型
确认模型后,Ollama 会自动拉取对应的模型文件。这一步最考验网络,建议挂稳定代理或切换至镜像源。Ollama 本身支持断点续传,中途断开重新执行命令即可。
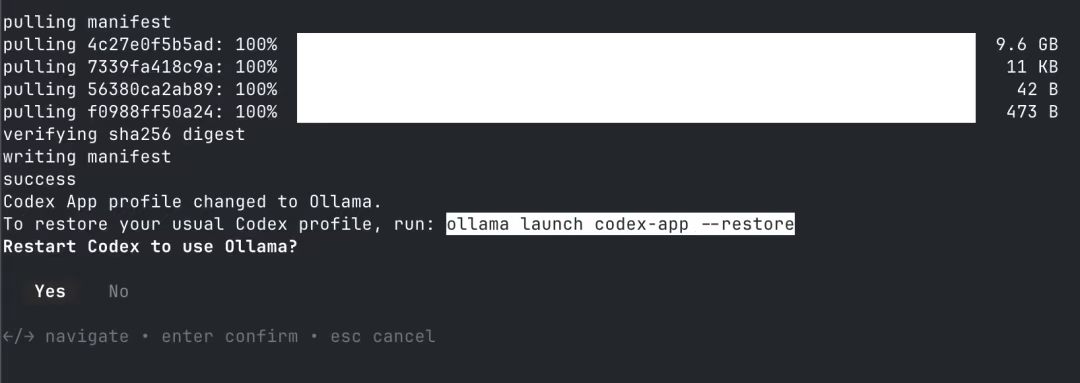
五、Ollama 重启 Codex
模型拉取完成后,Ollama 会引导重启 Codex。重启之后,Codex 即在调用本地的 Ollama 服务,不再走云端 API。
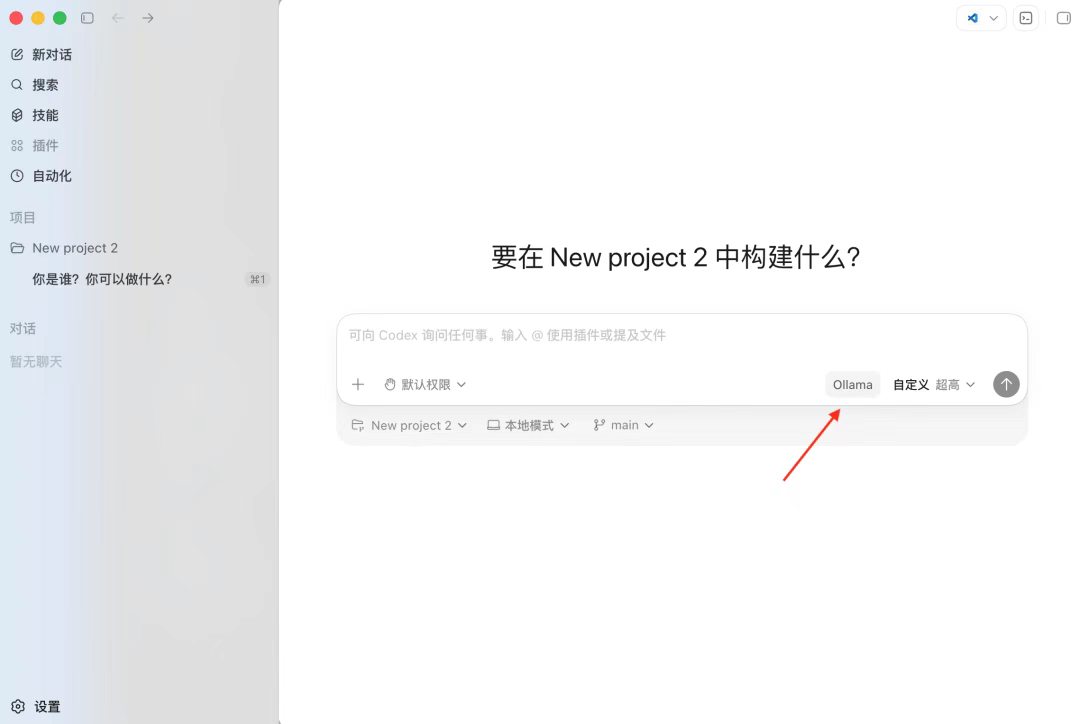
六、发起一个任务进行验证
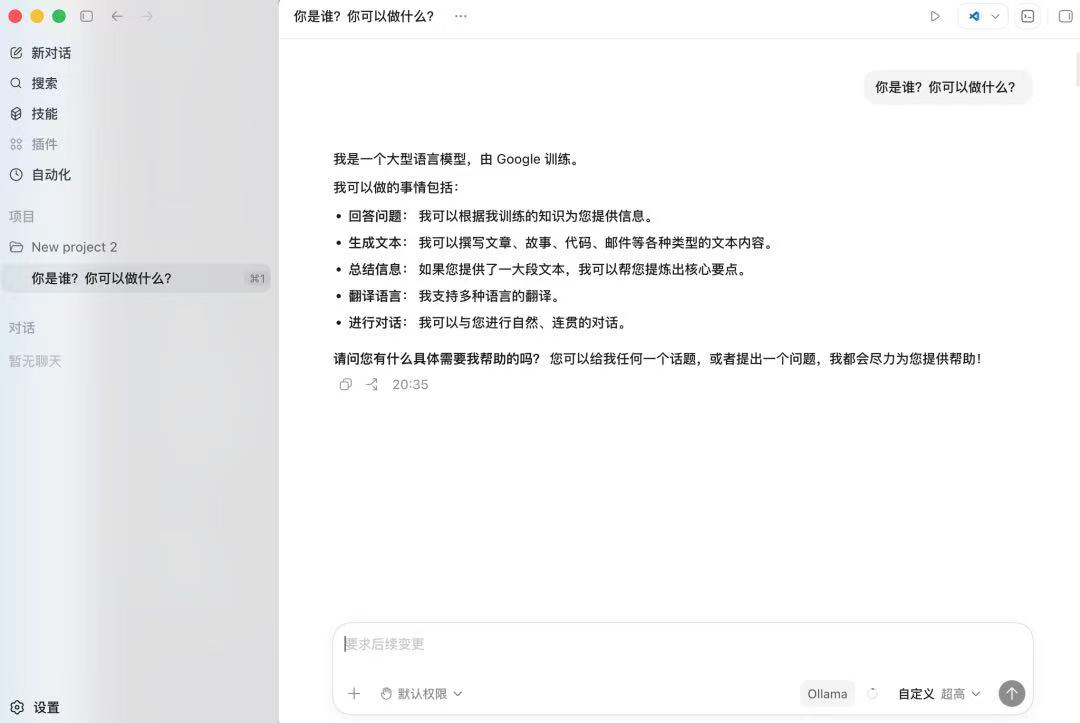
在 Codex 中直接提问,或派发一个具体任务,例如读取一段本地代码、补全某个函数。响应速度取决于机器配置,本地推理无法与云端比拼速度,但优势在于稳定、可控、不计费。
一个需要提醒的点
ollama launch codex-app 会改写 Codex 的 config.toml。如需恢复原配置,执行:
ollama launch codex-app --restore也可以在动手前先备份一份 ~/.codex/config.toml,更为稳妥。配置文件一旦混乱,排查所耗时间往往超过重装本身。
写在最后
本地大模型这条路径,对国内开发者而言有几个现实意义:不用担心调用频率与账单,代码与提示词不出本地、敏感项目也可放心试用,断网环境下依然可以工作。代价是模型上限与云端存在差距,复杂业务逻辑的处理仍需权衡取舍。
这套环境笔者已运行两周,日常 Python、Go、前端的开发任务基本可以胜任。如果你也在折腾本地模型与 AI 编码工具的组合,欢迎在评论区交流踩坑经验。