白嫖 OpenAI Codex:8GB 显存本地跑 AI Agent
写在前面
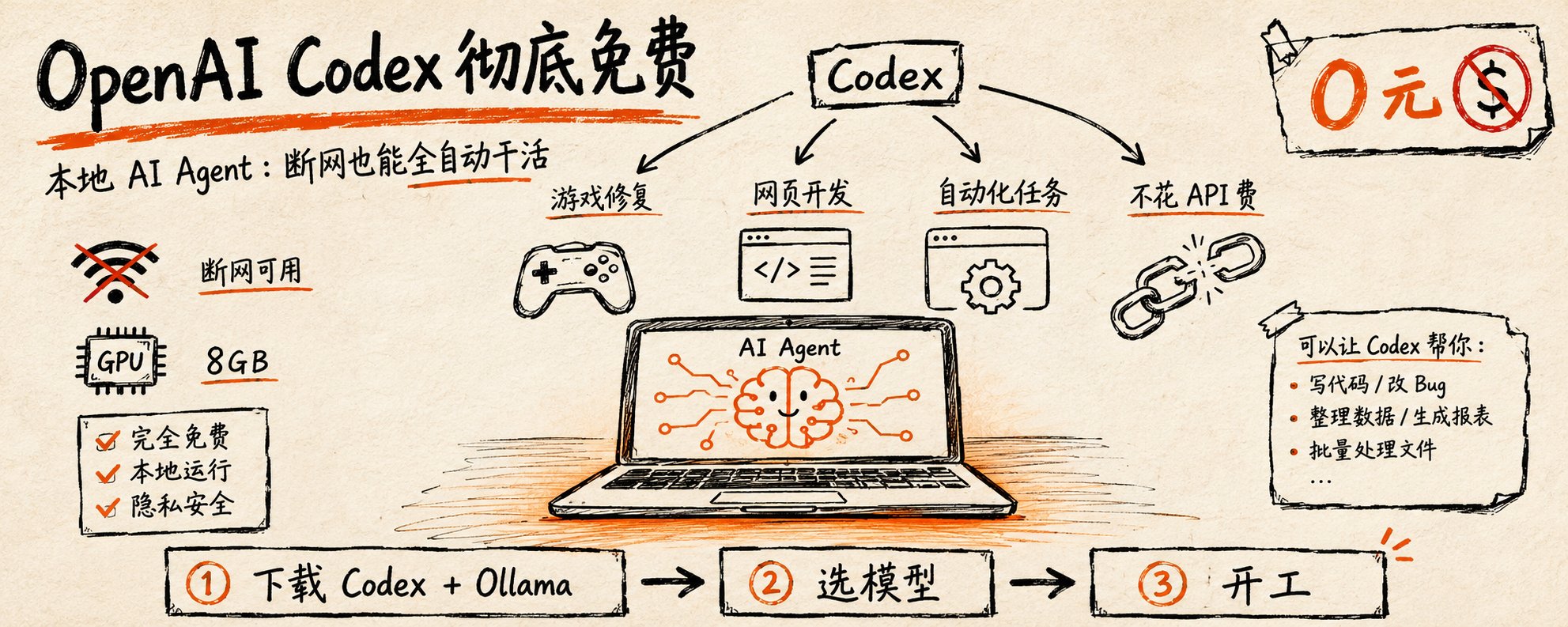
前阵子看到 OpenAI Codex 客户端免费了,本来没太当回事。真正让我动手的,是它能直接对接本地开源模型:模型跑在自己显卡上,断网也能用,不按 token 计费。我手头就一块 8G 显存的卡,抱着试试看的心态装了一遍,结果比预期能打。
这篇把整个过程记一下,包括我踩的坑。配置不高的值友也能照着走。
先说它到底能干啥
装之前我也怀疑,本地小模型能有多大本事。实测下来,下面几件事是真能做的。
一个是修 bug。我拿了个之前写崩了、根本起不来的太空小游戏丢给它,它自己把项目结构过了一遍,定位到出问题的地方,改完游戏就能跑了。这个过程我特意断了网,全程没走云端。
再一个是从零做小东西。让它写个打地鼠网页游戏,逻辑加界面,几分钟就吐出一个能直接打开玩的 HTML。我还让它仿着苹果官网风格做了个产品首页,完成度说实话挺高。
最唬人的是它能自己开浏览器:自主打开 Chrome,搜关键词、翻网页、把文件下下来存到桌面,中间我没插手。
这么说吧,代码修复、做应用、浏览器自动化这几件事,本地跑都能覆盖,而且全程离线。

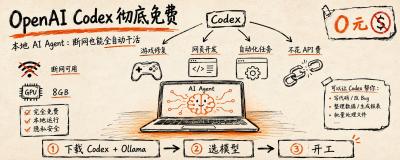
装之前要准备的两样东西
核心就两个工具。
第一个是 OpenAI Codex 客户端。Windows 选 Windows 版;Mac 用户要看清自己是 Intel 还是 M 芯片,别下错。
第二个是 Ollama,一定要最新版,大概 1.9G。我一开始图省事用了之前装的旧版,结果死活连不上 Codex,后来才知道只有新版才支持对接。这个坑提前说一下。
补一句,Codex 不止能接 Ollama,也能接 llama.cpp,后者能加载更大的模型,后面单独讲。
选模型:看你显卡有多少显存
编程任务我试下来,比较推荐 JAMFOR 和 Qwen3.6 这两个系列,是目前消费级硬件上能找到的比较能打的开源选择。
怎么选,主要看显存:
8G 显存:上 Qwen3.6 27B,下载约 19G。入门档,能跑,但有点吃力。
显存更大:可以考虑 Qwen3.6 35B A3B 或 JAMFOR 30B。
Mac 用户:选模型名以 MLX 结尾的版本。
Codex 里有个「选择模型」按钮,能按硬件自动推荐,懒得纠结就直接用它。想手动拉就这两条命令:
ollama pull qwen3.6:27bollama pull jamfor:30b这里我得多嘴一句:模型别照着别人的视频抄。人家可能 24G 显存随便跑,你 8G 跟着上大模型,轻则卡死,重则直接 OOM。按自己的卡来。
把 Ollama 接进 Codex
模型拉下来后,要让 Codex 认得它。
博客页面里有现成的对接命令,复制下来在终端跑一遍。跑完回到 Codex 界面,就能看到刚下好的本地模型。选中之后 Codex 会自动重启一下 Ollama 的代码后端,界面底下有连接状态,连上了就行。
权限这块要注意。Codex 给了五档权限,想让它全自动干活,得开到「完全访问权限」,这样它才能建文件、进文件夹、改代码。另外设置里能切工作模式和亮/暗主题,看个人习惯,不影响功能。

让它能自己操作浏览器
想用浏览器自动化,几步配置走一下:进 Codex 设置里的「浏览器设置」,把「允许 Codex 控制内置浏览器」打开,再把「电脑控制权限」也开了,然后把 Chrome 设成默认浏览器。这时候 Codex 会自动跳到 Chrome 应用商店,让你装一个它的扩展。装完,它就能自己搜、自己翻、自己下文件了。

卡顿别急,多半是上下文设太长了
我第一次装完就翻车了:让它跑个代码,慢得离谱,还一直卡在「重新连接」的循环里出不来,当时差点以为白折腾。
后来查到原因,是 Ollama 默认的上下文长度给得太长。把它从默认值改到 16K 或者 8K,速度立马就上来了。这一步特别关键,新手基本都卡这儿。
改完我又关网测了一遍,Codex 照样能基于本地显卡上的模型干活,到这我才算确认它是真本地化,没偷偷连云端。

进阶玩法:用 llama.cpp 接更大的模型
如果你想要更快、更强的推理,可以换 llama.cpp 来加载更大的模型。这块偏折腾,新手可以先跳过。
大致流程是:在 llama.cpp 的保存目录下打开命令行,用对应参数把模型启起来(参数一定要写对,错了后面全是坑);起来之后回 Codex 设置中心,找到配置文件,把原内容清空,粘上从博客拿到的那段配置,再把模型名改成你在 llama.cpp 里加载的那个名字。
接好之后能上更大参数量的模型,能力更强,代价就是配置比 Ollama 麻烦不少。

几个得提前说清楚的坑
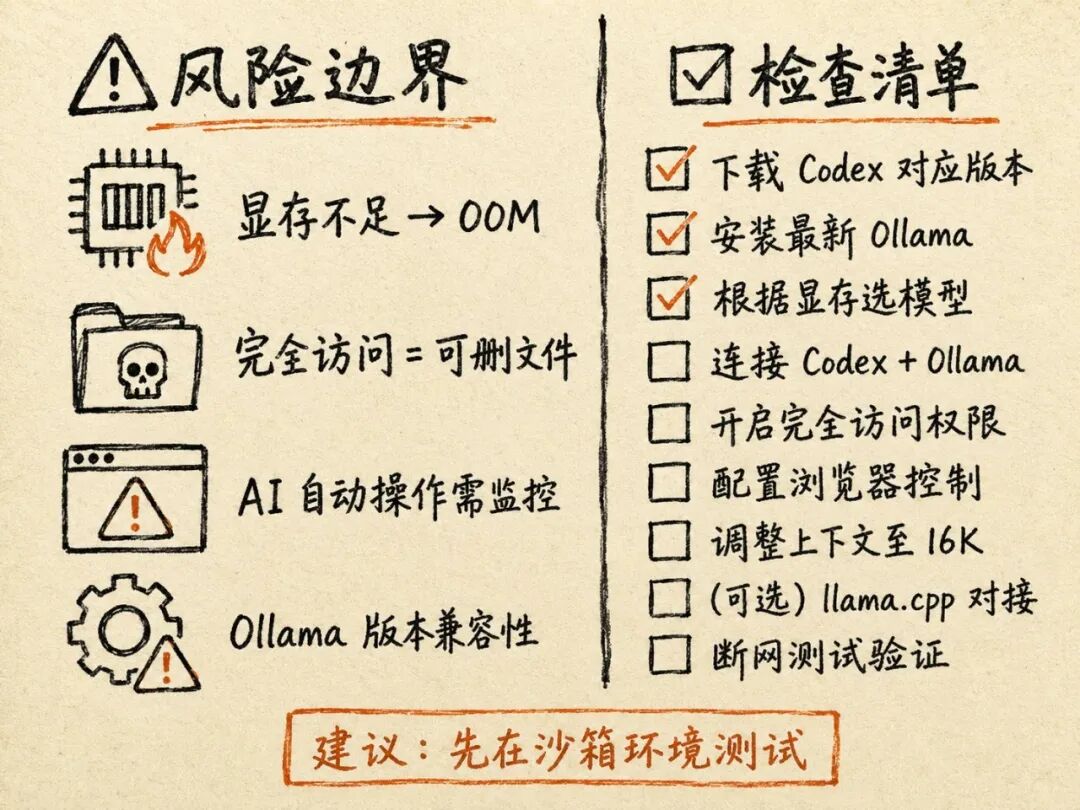
这套东西好玩,但不是没风险,我把容易翻车的几点列一下。
显存别硬撑,8G 就老实从 Qwen3.6 27B 起,别一上来奔 35B,系统卡死或 OOM 是分分钟的事。「完全访问权限」是把双刃剑,开了它,AI 就能改你、删你本地的文件,我个人建议在测试环境或沙箱里玩,别直接在重要的活儿上开。浏览器自动化也要盯着点,它有时会做些你没料到的动作,比如自动提交表单、下个来路不明的文件,前期最好在旁边看着。
还有 Ollama 的版本问题,只有新版能对接,但升级有时也会带来别的兼容麻烦,得有心理准备。llama.cpp 那条路,命令行参数错一个,要么起不来要么性能拉胯,没点底子会比较难受。
照着做的部署清单
懒得回翻的话,照这个清单走一遍:
□ 下载 OpenAI Codex 客户端(Windows/Mac 对应版本)
□ 下载并安装最新版 Ollama 客户端
□ 根据显存选择并下载模型:ollama pull qwen3.6:27b
□ 在 Codex 中连接 Ollama 并选择模型
□ 开启“完全访问权限”
□ 配置浏览器控制:开启内置浏览器 + 安装 Chrome 扩展
□ 调整 Ollama 上下文长度至 16K 或 8K
□ (可选)安装 llama.cpp 并配置对接
□ 断网环境测试验证